Here we are
As I described here, I was wonder-struck on how good the LLMs ran on my MacBook Pro.
note
NOTE: All the executable commands for bash/zsh are copied from openwebui or other respective official docs. If you don’t know what you are running, research it before you do!
l’attention
info
You will have to enable CPU Virtualization in your BIOS/UEFI settings. This is usually done by pressing a key like F2, F12, DEL, or ESC during startup. The exact key may vary depending on your MacBook model. Once in the BIOS/UEFI settings, look for an option related to CPU Virtualization and enable it. Save the changes and exit the BIOS/UEFI settings. However, this is only true for Intel/AMD CPUs. MacBooks with M-series processors appear to have them endabled by default.
I tried running the same docker command as posted on the previous article and it doesn’t setup ollama that is optimized for Apple Silicon. It was slow, as it wasn’t using the NPU/GPU or whatever they call those tensor/matrix circuits on SoC. It was using just the CPU. I had to install ollama bare-metal to get it to use the hardware-acceleration(HWA). Another slap in the face for trusting docker. I still run openwebui using docker but give access to the host’s zsh(??) to access ollama.
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:mainAnother crazy idea, we can run ollama externally on a server and only install openwebui on our system to use that. For that, we have to use this command below, replacing the actual URL we can access the remote ollama instance.
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=https://example.com -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:mainI know that there is a flag you can add to force docker to install GPU optimized version of ollama and I tried that but it doesn’t detect Apple’s SoC iGPU as GPU and throws an error, it doesn’t get the Metal API(Apple’s proprietary version of DirectX on Windows or Vulcan on Linux or the good old openGL that leverages HWA) version by default either.
I thought of doing a similar setup with the Mini-PC, unfortunately there are no optimizations for AMD’s iGPUs yet. However, there are optimizations for Intel’s ARC-based iGPUs. What this means is, if you buy a PC that is based on Intel processor that was released(on paper) in the last couple years(rewind back from Jan ‘25), chances are it has an inbuilt ARC-based iGPU and can perform better based on how much of the RAM is dedicated to the iGPU. That can be setup in the BIOS of the system you own.
Check vLLM and llama.cpp for updates on such technical details. I might do a run using those two tools later and completely drop the ollama wrapper, but I reckon that won’t make much difference to performance than my peace of mind as I get to have more control over what I am doing.
Models and their properties
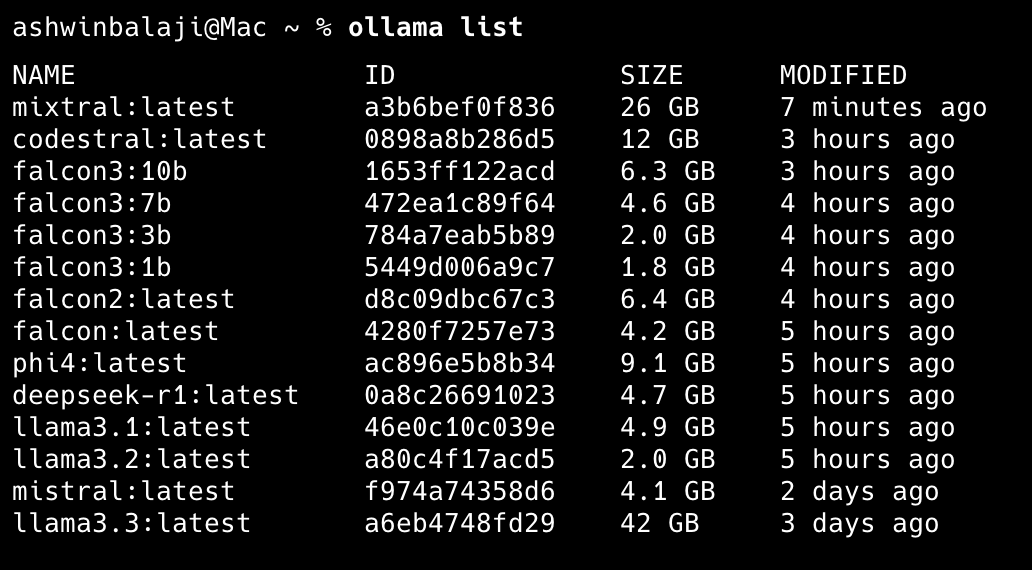
My tests are neither comprehensive nor representative of everyone’s needs. They represent topics and ideas that I usually want an opinion on or some insight I wish to nail that I overlooked in the past. The list of models I’m testing on my MacBook Pro are as follows:
-
llama3.3 -
llama3.1 -
mistral -
phi4 -
falcon3 -
mixtral -
codestral
I can classify the above list of models into 4 categories:
- Won’t Execute or Don’t Bother:
llama3.3,mixtral - 7B Parameters ~ 4-10 GB in Size and requires approximately +2GB of VRAM(GPU)/RAM(CPU) respectively: -
llama3.1,mistral,falcon3 - 14B Parameters:
phi4 - Addon Model:
codestral
All the tests were done with 20+ Chrome tabs open, Spotify playing music, Mathematica Notebooks open and a bunch of other stuff running in the background, so close to what and when I will be using. Your mileage may vary.
Test 01: General Thoughts and Insights
I have an interesting question to put forth for these models. I recently finished watching Silo Season 2. I started binge watching the series’ season 1, 3 weeks ago when I didn’t realise the season 2 was in the running. After finishing the season 1, I continued on with season 2 and loved every second. I loved the character Juliette Nichols, the protagonist of the series. After I finished watching, I was googling something about the series and came across some mean comments about the abovementioned character.
All those comments were true and are like another character I hate to my core, Rachel Green from Friends. So, I was astounded to see how I can like one and dislike another when they portray very similar characteristics. So, I came up with a rather long prompt that describes the situation and asks about why I liked one and not the other.
Results: All the models in 7B and 14B category and mixtral performed well, they explained different contexts why that is the case. However, llama3.3, which doesn’t run on my MacBook Pro simply because there isn’t much memory (although the system can create swap memory and use that to run it, more on that in the later part of the article), outperformed all the models, including what I presume is mistral-large-2 model that works when you use the Le Chat of Mistral AI website. It gave me a lot of open-ended questions think about this topic further on my own, and I like that more than just reading some standalone regurgitated answers. Here is the end of the response from llama3.3.

„A Mentat is a human computer, trained to perform complex calculations and analyses. They use questions to probe and understand the underlying patterns and structures of information.“ Know where this quote is from? Well, it is true for us too, not just mentats.
Of-course the screenshot above with the list of the models have more models than I have talked about so far. Here is a quick breakdown of those left-outs.
-
falconandfalcon2printed a couple of sentences - very dissatisfactory answers -
falcon3:1b,falcon3:3b,falcon3:10bwon’t print any answers -
llama3.2- printed a brief paragraph, but not sufficient to please me
So, for the next set of tests, these models are left out.
Test 02: Mathematics ~ Algebraic Topology
Here, before testing in my Laptop, I was querying some math related topics and sometimes the LLMs used LaTeX to print equations, which are more easy-going with the eyes than all the _, ^ and {} that comes out sometimes. So, there is a hack that can be leveraged. We give an extra System Prompt that will force the LLMs to use LaTeX when printing outputs. The prompt is as follows:
Use LaTeX for all mathematical expressions. For example, represent a quadratic equation as \( ax^2 + bx + c = 0 \).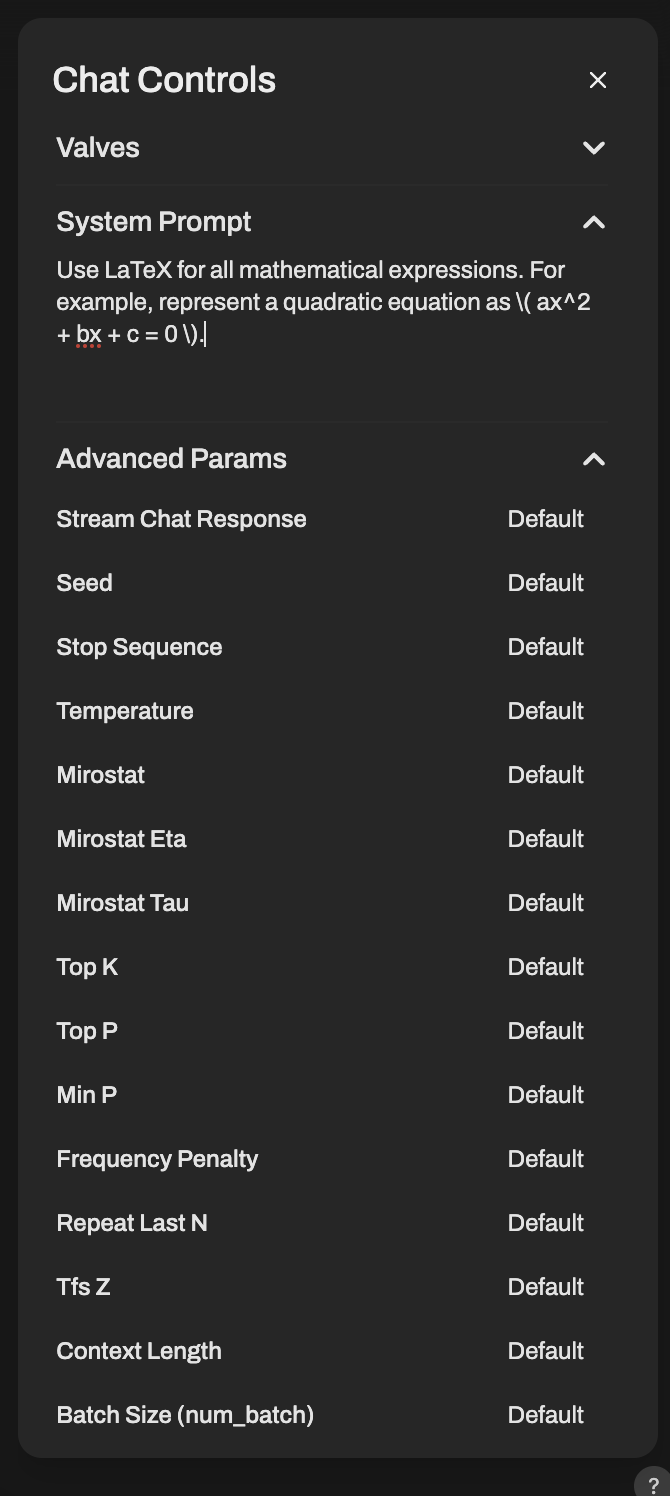
And the query is: what is the sum of Abelian groups in homology theory? demonstrate it with an example using $R^2$ and 2d torus as example topological spaces
Results: All the 7B and 14B models performed similarly, 14B running a tad bit slower. llama3.1 had problems with LaTeX syntax and half the answer turned red because of a syntax error. I re-ran the same prompt and only half the equations were in LaTeX and other half were just underscores and flowery brackets.
All faults of llama3.1 aside, it was the only model to give me a R-Language code to do the computations I asked for and some information on the packages I need to do so. I didn’t ask for it, but it is nice to learn how to do it with the help of a program. It reminds me of how we use Mathematica and xAct package to work with Einstein’s equations and differential geometry.
I like the answers from Mistral AI’s Le Chat for mathematically complex topics better, but we are talking about running LLMs locally and I can say I don’t have a preference unless I am biased towards mistral as it turns out it is by a corporation in France and I have some favorable predisposition towards French people and culture.
llama3.3 also performed similar to mistral-large-2 or, as I reference it as Le Chat in some places but it is marginally better than the ones I can run on my MacBook Pro. It wouldn’t be the reason to invest money in a dedicated LLM inference machine as it is very marginal gain for a vast sum of money.
However, when I asked a „Mathematical Physics“ query such as:
compute koszul tate resolution of cohomology for a free qed/maxwell theoryAlmost all the models failed. Only llama3.3and mistral-large-2gave proper answers. I wouldn’t blame LLMs for that, this is an extreme example and I would refer a textbook like „Quantization of Gauge Systems by Marc Henneaux and Claudio Teitelboim“ to learn the topic rather than trust the LLMs.
Check out the answers Le Chat provided here.
info
Nerd Alert: Or I could upload the PDF of the book and ask the LLM to do, but it is a resource heavy process as something called a „transformer“ should convert all the text into vectors (list of numbers if you will) and then convert the query also as vector, do a cosine search which tells what is the closest paragraph resembling the query, feed that data to LLM and LLM will give the answer to us. This is called RAG (Retrieval Augmented Generation).
Test 03: Programming
All the 7B and 14B models gave very satisfactory answers to the questions I asked them. One of the question was about HLS and SystemVerilog code generation to do some floating point operations on FPGA. These are highly specialized, but LLMs gave me a good starting point to work with.
Test 04: RAG
Will do it in the near future and update this section. This is to deal with Google Search and summarizing results. Say, we ask something about current events to LLMs, this method, using the „transformer“ will provide results. I find it useful at times to ask an LLM rather than search through the web.
What now?
For most use cases, I would say all the 7B or 14B parameter models gave very useful and satisfactory answers for everyday use. The only use case for larger parameter models is when you want some sort of philosophical discussion with open-ended questions that will help you stay inside your head, forgetting time passing by. Or to ask for a long complicated Mathematical Physics calculation only a few graduate physics students learn. Otherwise for all other cases, I feel comfortable to use just 7/14B parameter models for math and programming.
mixtral is a different kind of model. It is huge, and not really fit to run on my MacBook Pro. If you want to know about this specific model, try reading about „sparse mixture of experts model (SMoE)“. Look at the htop image below.
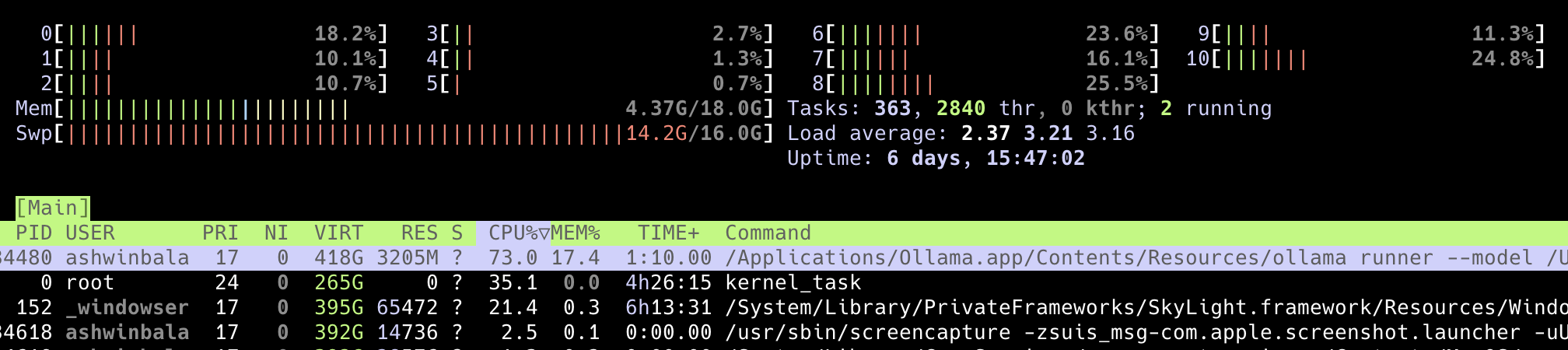
My MacBook Pro usually functions with 2GB of Swap memory, but because there isn’t enough memory to run it, it increased the swap memory size. Where did it come from? Part of my SSD storage. It is not good to rely on Swap memory. SSD’s data deletion procedure is just plain absurd, power hungry and damaging to electronic circuits. But thats the best we got and have to live with it. I might write an article about SSD’s data delete cycles in another article.
codestral is good for code completion, and needs to be setup with your favourite code editor. There are alternatives, but here comes my favorable predisposition to the French.
Remember why we are doing all this? We want privacy from the data-hoarding organizations. If you feel all this work is worth it, be my guest and go for it. It has been a delightful journey to learn about all this, and I probably will use local LLMs for most cases and use Le Chat for complex cases. Or wait for more powerful hardware becoming more affordable.