warning
Warning: Large image files, specifically 3 files that are each around 50MB in size, and aren’t in Dark Mode: don’t scorch your eyeballs.
Background
Recently, I use Gemini and ChatGPT frequently, with the former being more prominent. They save a lot of time on searching web to find answers. Before these LLMs, It was a great triumph to find an answer we are looking for just searching the web. Hours and hours of time spent reading different forums and the forbidden second and third page of search results from Google when the first page results don’t have the answers. It was a mission accomplished feel when we found answers at all. Today, LLMs have taken away such pleasures and provide us with concise answers in a few seconds.
However, data-hogging corporations provide both of the above LLMs as closed-source services. So, I tried to run LLMs locally on a machine I already have. I self-host a Plex Server on a Mini-PC that is a kind of over-speced. Here are the specifications of the said machine:
-
AMD Ryzen™ 7 4800H - 8c|16t processor
-
64 GB of Dual-Channel DDR4 3200MT/s RAM
-
512 GB Crucial NVMe SSD + 4 TB Crucial NVMe SSD (media library for Plex Server)
The only processes running on this server are Plex Server, Prometheus and Grafana. All these applications run bare-metal(no-virtualization or emulated environment like docker) using all the hardware resources. However, there is a small overhead for the Operating System as I installed the Ubuntu 24.04 LTS desktop version, which comes with proprietary encoding and decoding drivers for media streaming by default. I attempted a headless Fedora Server installation (no GUI, only terminal and SSH), installing all proprietary drivers for optimal performance, but I experienced persistent issues I’m unwilling to troubleshoot continuously. Default enabled hardware-encoding because of my Plex Pass Lifetime account. I have also setup the Plex server to „Hurt my CPU“ mode to use all the resources. However, I never saw CPU or RAM usage go beyond 15% and 10% respectively.
Prometheus and Grafana are used to monitor my Compute Cluster I had setup as explained here. I have some experience with using LLMs for some custom projects that never saw the light of the day, so I figured let me use this Mini-PC to self-host LLMs. I can migrate the plex server to a proper NAS device in the future.
Setup
Reluctantly, I installed the docker as the software. I had only supported that. I love to keep things bare-metal as it gives me more control over what’s happening in the system and my old habits as a Linux System Administrator. Docker is great if you are running 100s of services in your home lab and want to manage them efficiently. I don’t do that. Just a select few. So, I never use a docker except now I have to.
The softwares I needed to use are:
Luckily, there is an installation process that ties these two nicely in one simple command. I am running inferences on CPU only and don’t plan on adding a GPU; for reasons, see the last subsection of this article.
docker run -d -p 3010:8080 -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollamaI ran that in the Ubuntu’s Terminal Emulator and accessed it from my MacBook Pro as all of these devices are connected locally. However, If I haven’t mentioned already, I have Tailscale Zero-Tier VPN installed on this Mini-PC and other devices I own. This means I can access the webui as long as I am connected to the internet and have one of the devices on my hand.
Notice I have 3010 as port number rather than 3000 as provided by the openwebui documentation. I have Grafana using that port and don’t want to conflict that by running this service also on the same port. After few simple steps of creaing a local account and login, I was presented with a chat-like window to play around. I had to download the models themselves from the web, and so I did that. Once that is done, I was able to use local LLMs. Here are some screen recordings of some LLMs and how well they perform on this Mini-PC.
info
You will have to enable CPU Virtualization in your BIOS/UEFI settings. This is usually done by pressing a key like F2, F12, DEL, or ESC during startup. The exact key may vary depending on your MacBook model. Once in the BIOS/UEFI settings, look for an option related to CPU Virtualization and enable it. Save the changes and exit the BIOS/UEFI settings. However, this is only true for Intel/AMD CPUs. MacBooks with M-series processors appear to have them endabled by default.
Test Run
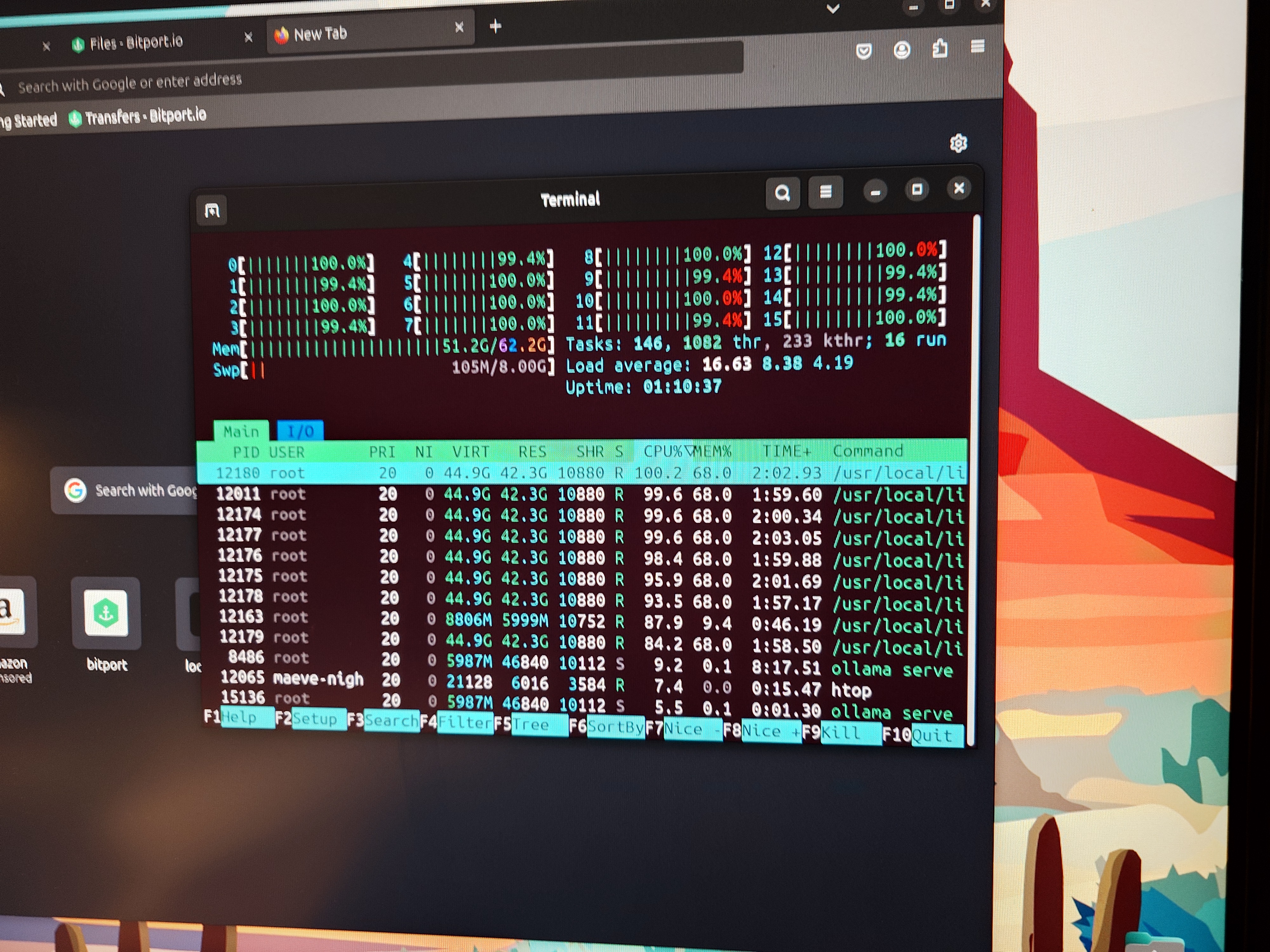
The above images represent test run and the system resource usage. I shall update the power drawn by the system in the near future.
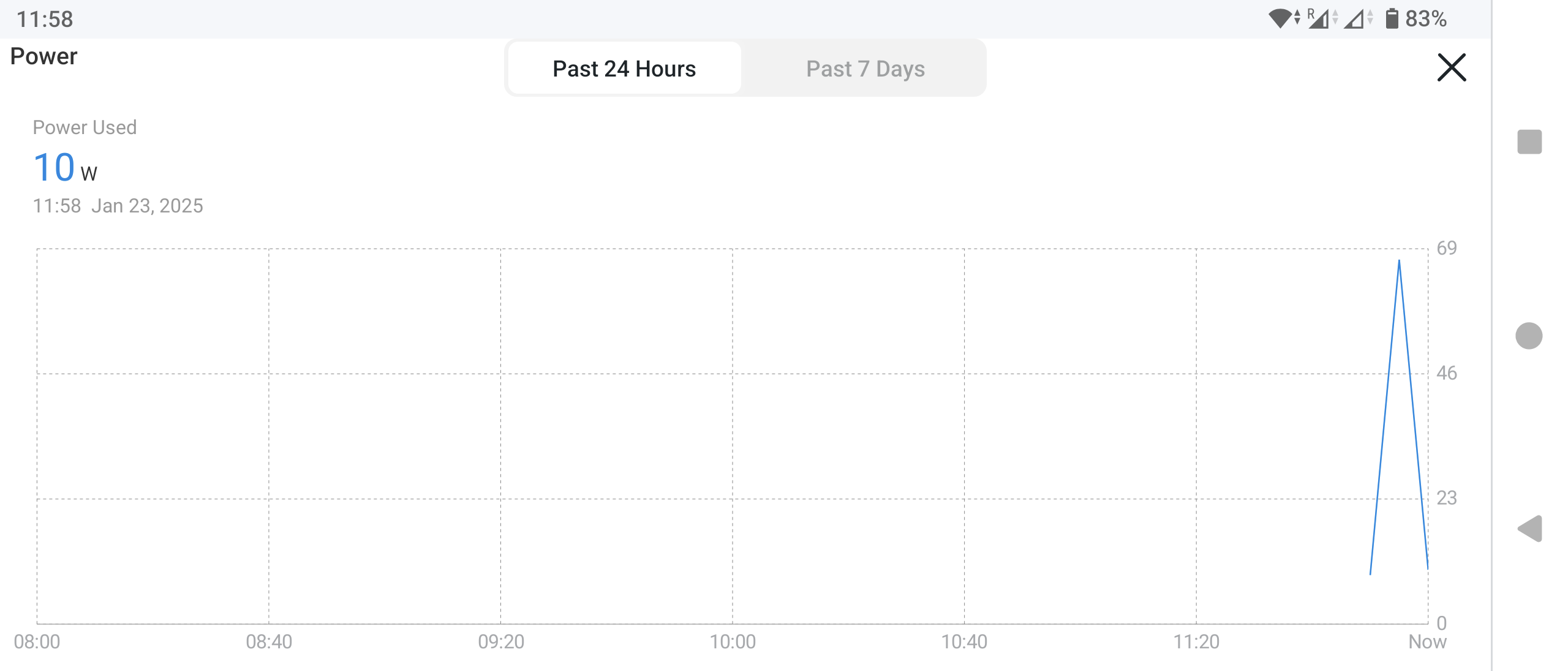
EDIT: I have measured the power draw for the usage of LLMs on this Mini-PC. It idles around 5-8W and when LLMs are inferenced, it draws around 55-70W of power.
llama3.3

The above image is 30x speed and the actual time it took to provide the complete answer was 00:26:09.
mistral

This is in real time. Elapsed time: 00:01:16. mistral seems fine for normal use cases.
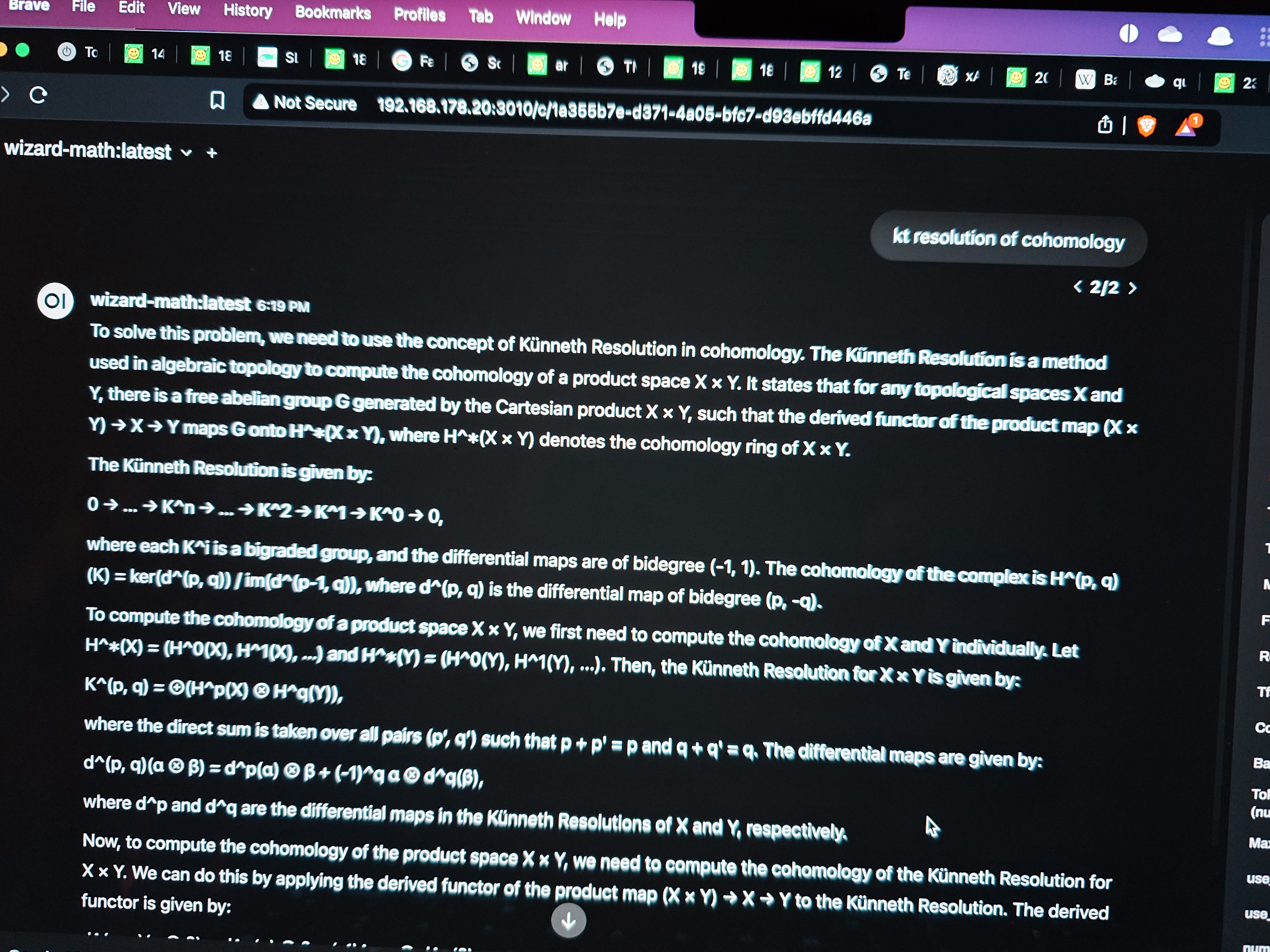
wizard-math

This is also in real time. Elapsed time: 00:04:20. This seems to provide more mathematical data and is interesting for me to look further into it.
Results
I like llama3.3 more than Gemini Flash 2.0 Experimental or ChatGPT 4o. It does take a lot of time to start to give any output, but once started, it is a slow-streamlined output. It is a 70B parameter model, so I intened to use it only occasionally. I can use mistral or wizard-math or qwen2-math for most use cases as they are just 7B parameter models. 10x less parameters don’t imply 10x faster inference, it happens to be 20x faster inference or 5x faster inference (mistral and wizard-math) respectively in the above example. Generally, it is faster than more parameters. I believe that the first response takes some time as the model needs to be loaded onto the system memory to start processing. I reason this on the basis that the subsequent inferences don’t take such long times. A point to note, the fans start to run at full speed and it is a high-pitched noise that may be annoying to many. If that is the case, then I would recommend you place this somewhere else than the workplace.
What would I do different to improve this setup?
There are two ways to improve upon this performance choosing a different hardware setup.
Firstly, I might get a more recently released CPU that has some sort of AI accelerator circuits built into it that also supports DDR5 memory to improve the inference, both in terms of performance and due to faster memory. This is still cheaper than buying a GPU to run inference - it may be fast but where would you go for a GPU with 96 GB of RAM? One can consider the Mac-Mini or Mac Studio like described here but this CPU-based inference sounds more budget-friendly than other alternatives. Running on a x86-64 platform is energy hungry compared to a Mac Studio, but not definitive as it can be different depending on the hardware choices.
Secondly, which happens to be eco-friendly(to an extent), get a used server rack like this for example. Upgrade it with 256 GB of RAM, then you got a beefy boi who has 28 cores of CPU that can eat away any LLM more comfortably. As I recall, llama3.3 only requires a 141GB of RAM memory to run without quantization(full floating point precision), hence this system, albeit very annoyingly loud, can perform so much faster and better for 700€ expense at just 500W of power draw. Eco-friendly because you get to use something that is about to be thrown out as e-waste for couple more years. If LLMs get huge, which it will, all we have to do is slot in more RAM into this system as it has 24 slots to fill!!
I can’t think of anything else to run LLMs locally.
Updates
Turns out, my M3 Pro MacBook Pro with 18GB RAM is more optimized to run mistral and wizard-math and is more usable than the whole Mini-PC setup. However, I can only run small models and/or large models that are quantized(quantized ~ reducing the precision of the parameters of every node of the neural network) which have low precision and that implies not appropriate answers. At this point all my thoughts are subjective and I’ll do some test runs to see how much I can salvage from my laptop, perhaps write another article soon.